Data in Schema
There is a lot of data, in various types, that can be used in workflow schema definitions. It can be accessed in two ways:
- via context that is passed to
stagefunction in stage code, - using string interpolation.
Context
In the example code for the stage, a ctx object is passed to the
stage function. This context object allows access to various types
of data.
def stage(ctx):
if ctx.flow.kind == 'ci':
systems = ["ubuntu:22.04", "debian:bullseye", "fedora:37", "rockylinux:8"]
else:
systems = ["ubuntu:22.04"]
return {
"parent": "root",
"triggers": {
"interval": "10m",
},
"jobs": [{
"name": "hello job",
"steps": [{
}, {
"tool": "shell",
"cmd": "echo 'hello world'"
}],
"environments": [{
"executor": "docker",
"system": systems,
"agents_group": "all",
"config": "default"
}]
}]
}
Interpolation
def stage(ctx):
return {
"parent": "root",
"triggers": {
"interval": "10m",
},
"jobs": [{
"name": "job for branch #{branch.branch_name}",
"steps": [{
"tool": "shell",
"cmd": "echo 'hello world'"
}],
"environments": [{
"system": "ubuntu-18.04",
"agents_group": "all",
"config": "default"
}]
}]
}
In this example, there is a branch.branch_name
variable. Interpolation inside a string is done using the #{...}
operator (hash and curly brackets, which is similar to Ruby's variable
interpolation in strings).
User variables can be defined as parameters in stages (see Parameters section in Workflow Schema chapter). Then they can be accessed using their name in uppercase.
Data Overview
There is several types of data:
- environment variables
- secrets
- workflow objects:
project,branch,stage,flow,run,jobandstep - user parameters, these are input parameters to a stage that can be provided by a user manually
- user data, data kept server-side that can be stored, update, manipulated and used by workflow steps
Environment Variables
Environment variables are stored in a branch. They can be accessed in three ways:
- traditionally, as environment variable in a shell:
"$MY_VAR", - via string interpolation:
"#{env.MY_VAR}", - via context:
ctx.env.MY_VAR.
Example:
def stage(ctx):
return {
"parent": "root",
"triggers": {
"parent": True,
},
"parameters": [],
"configs": [],
"jobs": [{
"name": "Env vars",
"steps": [{
"tool": "shell",
"cmd": "echo $MY_VAR"
}, {
"tool": "shell",
"cmd": "echo '#{env.MY_VAR}'"
}, {
"tool": "shell",
"cmd": "echo '" + ctx.env.MY_VAR + "'"
}],
"environments": [{
"system": "any",
"agents_group": "all",
"config": "default"
}]
}]
}
More about environment variables can be found in Environment Variables chapter.
Secrets
The values of secrets defined in a project can be accessed in the following way:
| Secret Type | Access |
|---|---|
| Simple | From context: ctx.secrets.<secret name> or via string interpolation: #{secrets.<secret name>}, e.g. ctx.secrets.access_token |
| SSH Key | From context: ctx.secrets.<secret name>.user and ctx.secrets.<secret name>.key or via string interpolation: #{secrets.<secret name>.user} and #{secrets.<secret name>.key}, e.g. ctx.secrets.github_creds.user |
Legacy approach:
| Secret Type | Legacy Access |
|---|---|
| Simple | #{KK_SECRET_SIMPLE_<secret name>}, e.g. #{KK_SECRET_SIMPLE_access_token} |
| SSH Key | #{KK_SECRET_USER_<secret_name> and #{KK_SECRET_KEY_<secret_name>}, e.g. #{KK_SECRET_USER_gitlab} and #{KK_SECRET_KEY_gitlab} |
More about secrets can be found in Secrets chapter.
Workflow Objects Data
Project
In context: ctx.project.<field-name>, in string interpolation: #{project.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a project |
created | Creation date and time |
name | Name of a project |
description | Description of a project |
data | User data, see User Data section |
The example of this data can be seen in the screenshot below. This screen displays a Project page with the Data tab open.
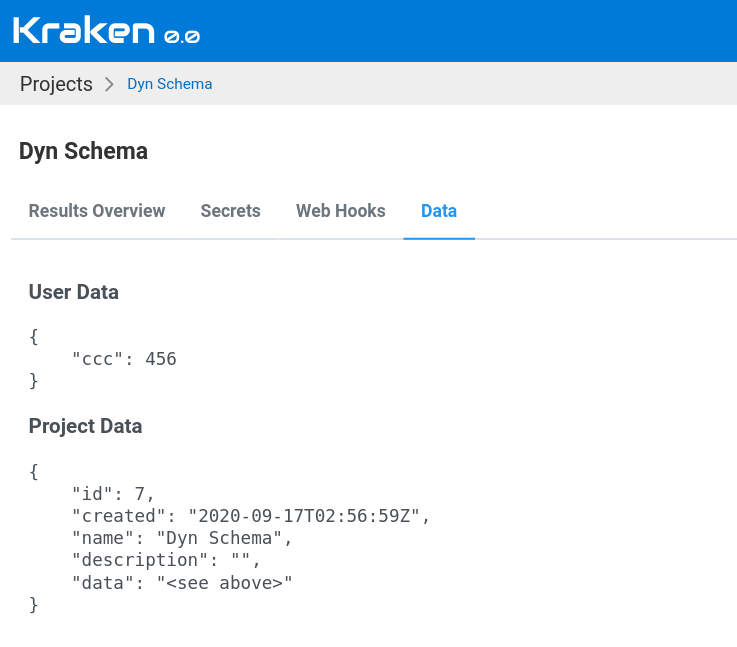
Branch
In context: ctx.branch.<field-name>, in string interpolation: #{branch.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a branch |
created | Creation date and time |
name | Display name of a branch |
branch_name | A name of a branch in a repository |
retention_policy | Retention policy definition |
data | User data shared for a branch, see User Data section |
data_ci | User data only related with CI flows, see User Data section |
data_dev | User data only related with Dev flows, see User Data section |
The example of this data can be seen in the screenshot below. This screen displays the Branch Management page, specifically the Data tab.
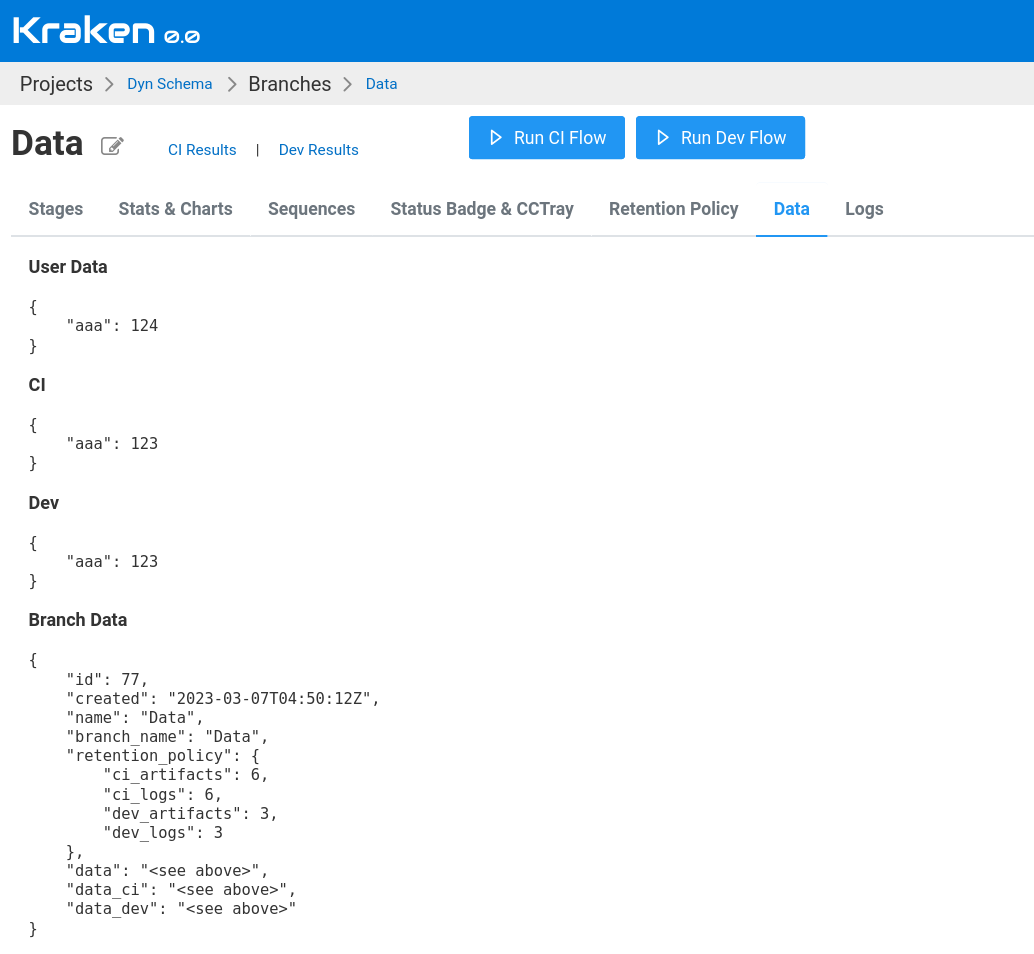
Stage
In context: ctx.stage.<field-name>, in string interpolation: #{stage.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a stage |
created | Creation date and time |
name | Name of a stage |
description | Description of a stage |
The example of this data can be visible on the screenshot below. This screen shows a Branch Management page, the Data tab of the selected stage.
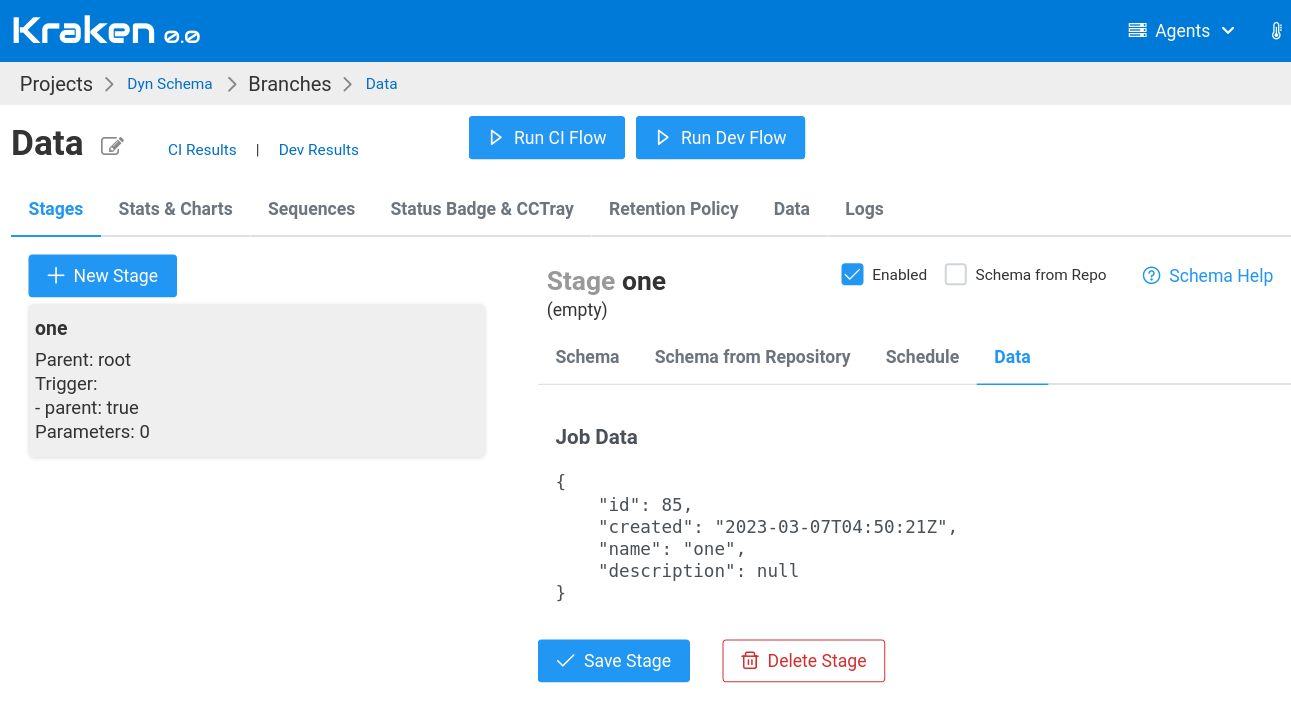
Flow
In context: ctx.flow.<field-name>, in string interpolation: #{flow.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a flow |
created | Creation date and time |
kind | Kind of a flow, ci or dev |
trigger | Trigger event information |
seq | Sequence number for a flow, see Flow and Run Sequences section |
data | User data, see User Data section |
The example of this data can be seen in the screenshot below. This screen displays a Flow page with the Data tab.
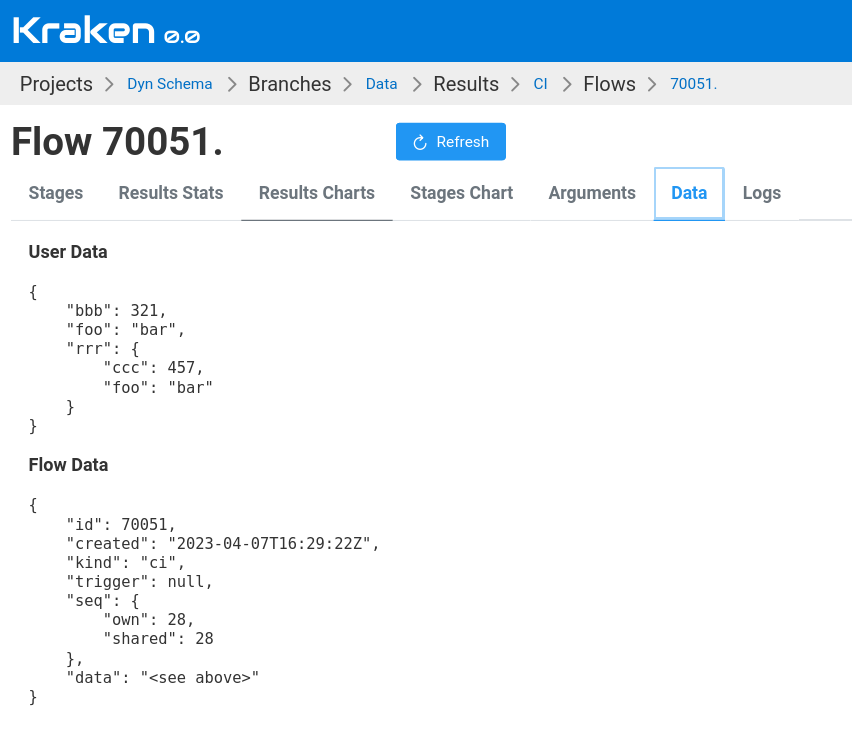
Run
In context: ctx.run.<field-name>, in string interpolation: #{run.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a run |
created | Creation date and time |
seq | Sequence number for a run, see Flow and Run Sequences section |
The example data can be seen in the screenshot below. This screen displays a Flow page, with the Data tab selected for the specific run.
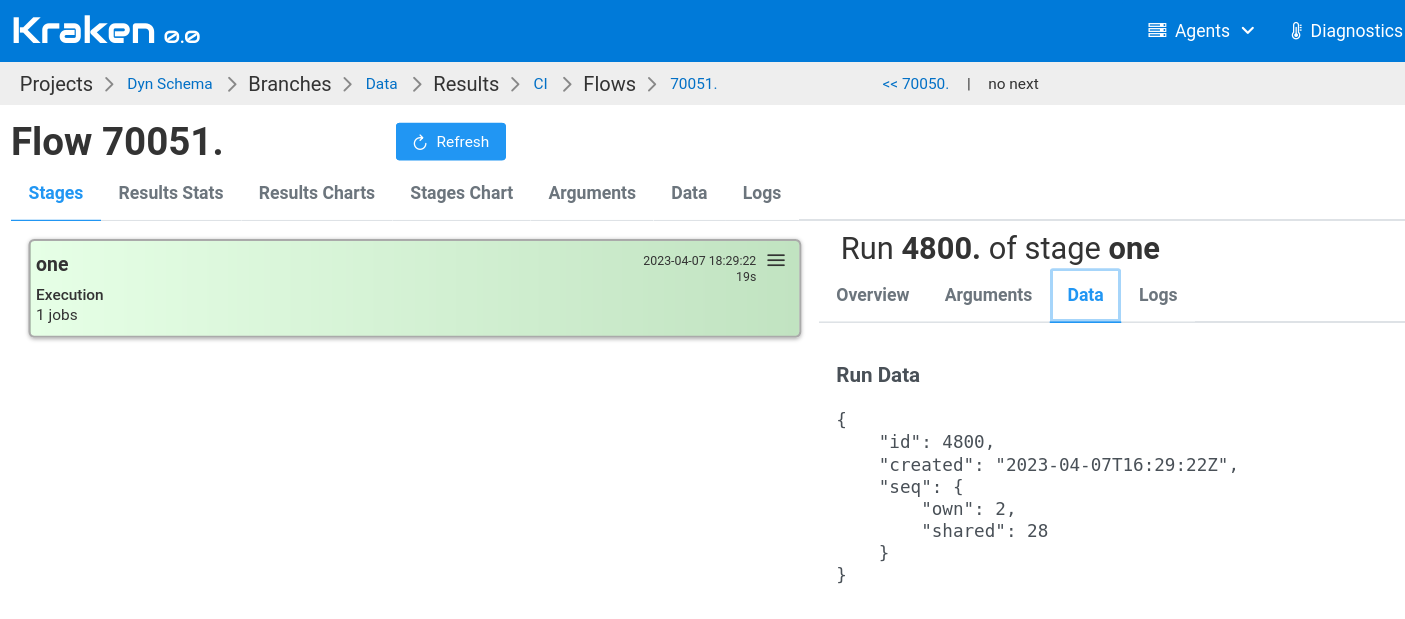
Flow and Run Sequences
Flows and Runs has predefined sequences that are incremented with each new flow or run. Additionally, there variants specific to flow kinds such as CI and DEV.
| Sequence Name | Deprecated Name | Description |
|---|---|---|
flow.seq.shared | KK_FLOW_SEQ | A variable that returns a sequence value for flows. The sequence is incremented with each flow regardless of its type, ie. it is shared between flow types. |
flow.seq.own | KK_CI_DEV_FLOW_SEQ | A variable that returns a sequence value for flows. The sequence is incremented with each flow of given type (CI/DEV), ie. it is handled separately for each flow type. |
run.seq.shared | KK_RUN_SEQ | A variable that returns a sequence value for runs of given stage. The sequence is incremented with each run regardless of flow type, ie. it is shared between flow types. |
run.seq.own | KK_CI_DEV_RUN_SEQ | A variable that returns a sequence value for runs of given stage. The sequence is incremented with each run of given flow type (CI/DEV), ie. it is handled separately for each flow type. |
Example:
{
...
"flow_label": "bld-#{flow.seq.own}",
...
}
Job
In context: ctx.job.<field-name>, in string interpolation: #{job.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a job |
created | Creation date and time |
name | Name of a job |
steps | A list of steps. More details below, in Step section. |
The example of this data can be seen in the screenshot below. This screen displays the Run page and the Data tab of the selected job.
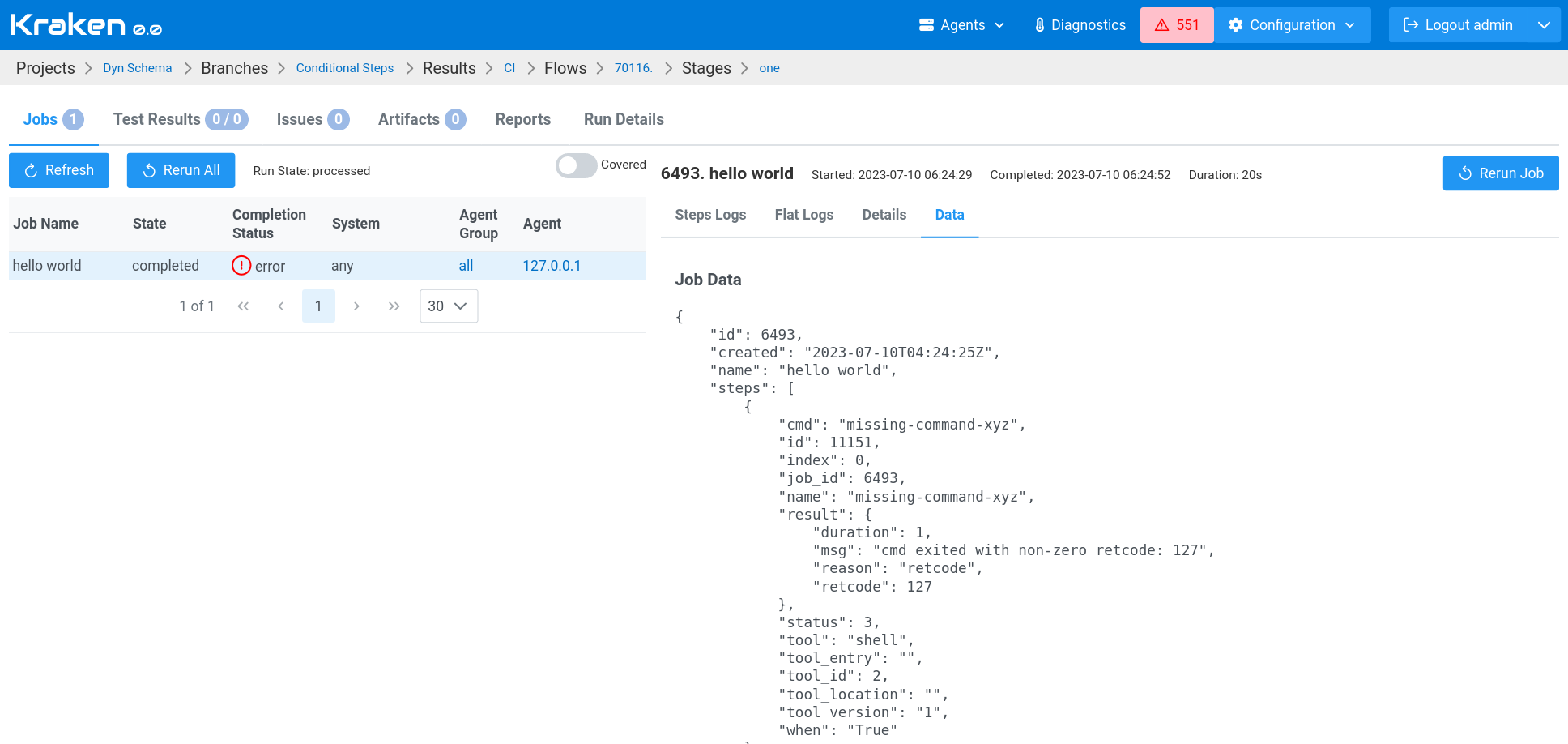
Step
In context: ctx.step.<field-name>, in string interpolation: #{step.<field-name>}.
Available fields:
| Field | Description |
|---|---|
id | Database ID of a step |
index | Index of a step in a steps list, starts from 0 |
tool | A name of a tool that is used in this step |
cmd | Command that was executed in step |
job_id | Job ID in database |
name | Name of the step |
result | Result of the step execution |
result.duration | Duration of the step |
result.msg | Error message. Present only when the step erred. |
result.reason | Reason of the error. Present only when the step erred. |
result.retcode | Return code of the step executing process. Present only when the step erred and returned non-zero return code. |
status | Execution status, integer. 0 - not started, 1 - in progress, 2 - done (success), 3 - error (failure), 4 - skipped (also treated as success). |
The example of this data can be seen in the screenshot above. This screen displays the Run page and the Data tab of the selected job.
Other
Available fields:
| Field | Description |
|---|---|
is_ci | True if this is CI flow, otherwise False |
is_dev | True if this is Dev flow, otherwise False |
User Parameters
The description for defining user parameters can be found in the Parameters section in Schema chapter.
Arguments provided for user parameters can be accessed from a context
(ctx.args.<arg-name>) and also using string interpolation (#{args.<arg-name>}).
The following examples show how arguments can be used in a stage code.
Example 1
Accessing user arguments from the context:
def stage(ctx):
if ctx.args.testing_scope == 'full':
systems = ["ubuntu:22.04", "debian:bullseye", "fedora:37", "rockylinux:8"]
else:
systems = ["ubuntu:22.04"]
return {
"parent": "root",
"triggers": {
"interval": "10m",
},
"parameters": [{
"name": "testing_scope",
"type": "string",
"default": "full",
"description": "Scope of tests. 'full' or 'limited'."
}],
"jobs": [{
"name": "hello job",
"steps": [{
"tool": "shell",
"cmd": "echo 'hello world'"
}],
"environments": [{
"executor": "docker",
"system": systems,
"agents_group": "all",
"config": "default"
}]
}]
}
Here, the testing_scope user parameter is used to determine the
scope of testing. If the user provides the value full for
testing_scope, then testing will be conducted across several
operating systems. Otherwise, testing will be limited to a single
system.
At first glance, it may look weird that the argument is being used in the if condition before being defined. The stage function is executed multiple times at different time intervals. During the very first execution, all variables in the context are, by default, set to zero. Therefore, in that execution round, the parameters are defined. In the next execution, the parameters are defined, and their default or user-provided values are known.
Example 2
Using string interpolation:
def stage(ctx):
return {
"parent": "root",
"triggers": {
"interval": "10m",
},
"parameters": [{
"name": "count",
"type": "string",
"default": "10",
"description": "Number of tests to generate"
}],
"jobs": [{
"name": "random tests",
"steps": [{
"tool": "shell",
"cmd": "echo 'the count is #{args.count}'"
}, {
"tool": "rndtest",
"count": "#{args.count}"
}],
"environments": [{
"executor": "docker",
"system": systems,
"agents_group": "all",
"config": "default"
}]
}]
}
In the parameters section, the count parameter is defined. Then,
in the steps, it is used via string interpolation, i.e. #{args.count}.
User Data
Instructions on how to manipulate user data can be found in the Data tool section in Schema chapter.
User data that has already been stored can be accessed from the stage context and through string interpolation.
Example 1
Using data from stage context:
def stage(ctx):
jobs = []
for ts in ctx.flow.data.tests:
jobs.append({
"name": "tests %s" % ts,
"steps": [{
"tool": "shell",
"cmd": "echo 'run tests %s'" % ts
}],
"environments": [{
"executor": "docker",
"system": "ubuntu:22.04",
"agents_group": "all",
"config": "default"
}]
})
return {
"parent": "root",
"triggers": {
"parent": True,
},
"jobs": jobs
}
In this example, the tests data should have already been set or
updated in the current flow, for example, in a previous stage where
the scope of tests was acquired from some external source. Now, in the
current stage, this acquired scope is being used to define jobs in the
for loop.
Check full example code on https://github.com/Kraken-CI/workflow-examples/tree/main/dynamic-schema