Autoscale in Cloud
Kraken CI allows for creating executing machines dynamically in the cloud when they are needed. They can be either virtual machines or containers. When new jobs are triggered and there are no agents available for them, new machines with Kraken agents are spawned. The configuration of the way of spawning new machines is located in agent groups.
Currently, Kraken CI autoscaling is supporting:
- AWS EC2 virtual machines
- AWS ECS containers
- Azure virtual machines
- Kubernetes
Preparing Cloud Environment
- AWS EC2
- AWS ECS
- Kubernetes
In the case of AWS EC2, it is required to assign proper permissions to the accessing user so that Kraken can create or destroy EC2 instances. The list of all requires permissions looks as follows:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CreateKeyPair",
"ec2:CreateSecurityGroup",
"ec2:CreateTags",
"ec2:DeleteKeyPair",
"ec2:DescribeInstances",
"ec2:DescribeInstanceStatus"
"ec2:DescribeInstanceTypeOfferings",
"ec2:DescribeRegions",
"ec2:DescribeSecurityGroups",
"ec2:DescribeVpcs",
"ec2:RunInstances",
"ec2:TerminateInstances",
],
"Resource": "*"
}
]
}
In the case of AWS ECS, it is required to assign proper permissions to the accessing user so that Kraken can create or destroy ECS tasks. The list of all requires permissions looks as follows:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ec2:DescribeNetworkInterfaces",
"ecs:RunTask",
"ecs:StopTask",
"ecs:DescribeTasks",
"ecs:ListTaskDefinitions"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::*:role/ecsTaskExecutionRole"
}
]
}
For Kubernetes, there are two accessing variants: Kraken CI is installed inside Kubernetes cluster or outside. In both cases, a proper access must be configured. When Kraken is installed inside a Kubernetes cluster then this is made using Helm chart and it also sets service account and proper permissions. When Kraken CI sits outside of Kubernetes cluster, then the service account and permissions must be configured in the following way.
The content:
apiVersion: v1
kind: Namespace
metadata:
name: <namespace>
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kraken
namespace: <namespace>
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kraken-role
rules:
- apiGroups: [""]
resources: ["nodes", "services", "pods", "endpoints", "namespaces"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kraken-crb
roleRef:
kind: ClusterRole
name: kraken-role
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: kraken
namespace: <namespace>
should be copied and pasted to kraken-serviceaccount.yaml file or
downloaded from here. Before creating
the resources, set your namespace by replacing all occurrences of
<namespace> with e.g. kraken.
And then create these resources using kubectl:
kubectl apply -f kraken-serviceaccount.yaml
This will create:
- an indicated namespace (e.g.
kraken), - a service account
kraken, - a cluster role
kraken-rolethat allows browsing nodes, services, pods, endpoints and namespaces, and creating and deleting pods, - cluster role binding
kraken-crbthat assignskraken-rolerole tokrakenservice account
Service account's token will be used in the next steps.
Global Cloud Settings
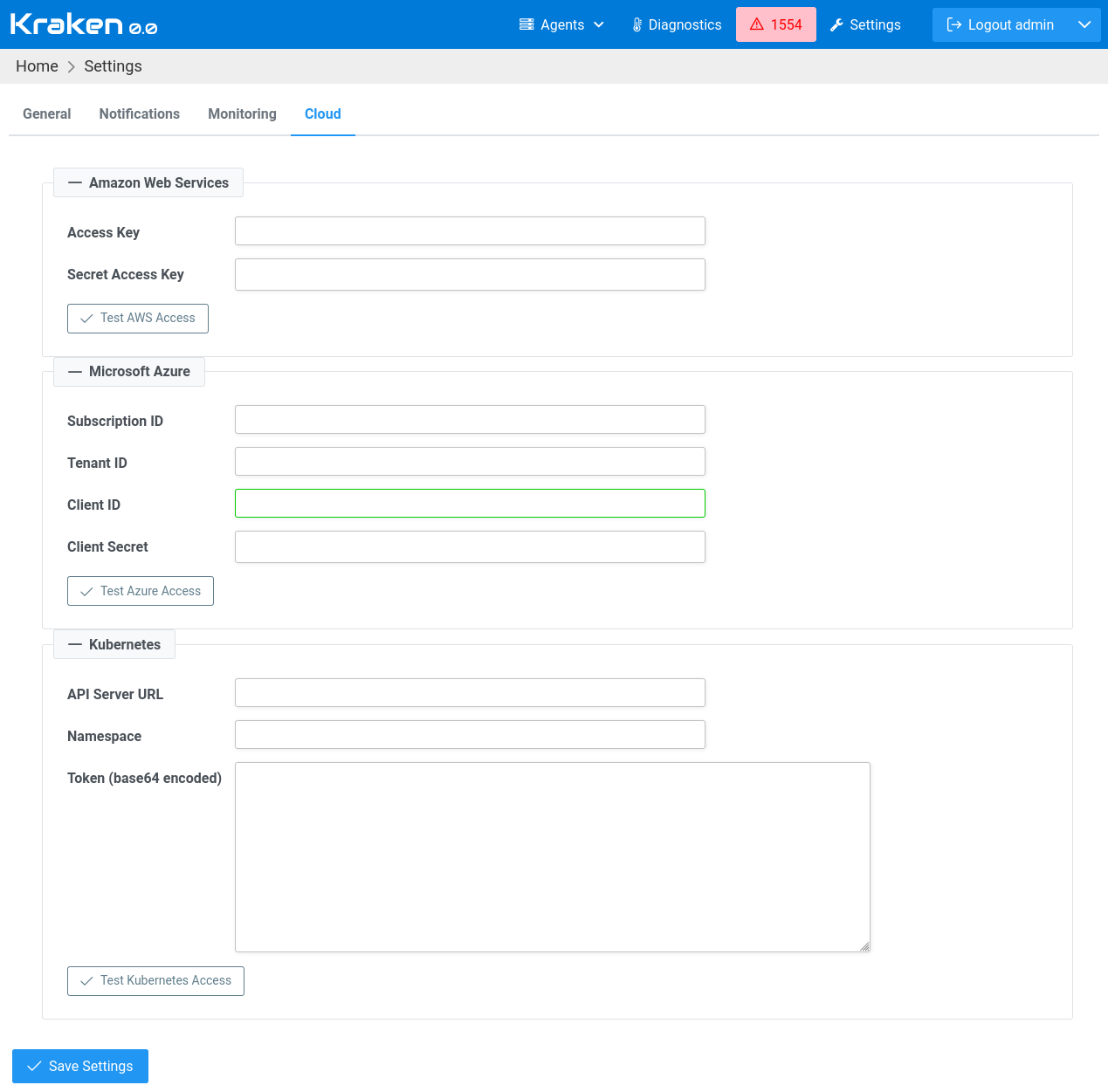
First, global settings must be set to allow access to a given cloud provider. In Web UI, on Kraken -> Settings page, in Cloud tab, there is a form for collecting credentials to cloud providers:
- AWS
- Azure
- Kubernetes
In the case of AWS, Access Key and Secret Access Key are required.
When Microsoft Azure is used, then there are required Subscription ID,
Tenant ID, Client ID and Client Secret.
When Kraken is installed inside Kubernetes cluster, then only setting
Namespace field is required, API Server URL must be empty.
When Kraken is running outside of Kubernetes cluster then all fields
are required: API Server URL, Namespace and Token. Namespace
and Token were created in previous steps. The following commands will
reveal the token.
First, check the definition of kraken service account:
kubectl get serviceaccounts/kraken -n <namespace> -o yaml
This should display a list of secrets at the bottom. The token should
be stored in a secret with a name in the form kraken-token-XXXXX
like e.g. kraken-token-5fvcb.
Now retrieve the token value:
kubectl get secret kraken-token-XXXXX -n <namespace> -o yaml
The value should be under the token field, and it should be pretty long. It is encoded using base64, and in this form, it should be copied & pasted to Kraken CI cloud settings (no decoding is required).
Preparing VM Image
In the case of VM environments, an operating system image needs to be
prepared. For example, in the case of AWS EC2, this image is called
AMI (Amazon Machine Image). There are certain requirements that this
image needs to meet in order to run a Kraken Agent. It should have
Python and Git preinstalled. Additionally, the generated image should
be capable of running a user data script during the initial
boot. This script is used to install the Kraken Agent and your own
init script (which can be passed via Kraken).
- AWS EC2
This is an example Packer script for preparing AMI with Ubuntu:
https://github.com/Kraken-CI/kraken/blob/master/base-images/aws-ec2/aws-ubuntu.pkr.hcl
And here, you can find an example script for Ansible that prepares an AWS AMI image for Windows with all the dependencies included:
https://github.com/Kraken-CI/kraken/tree/master/base-images/aws-ec2-win-ansible
Configuration in Agents Groups
Having set credentials to cloud providers, it is possible now to
configure the aspects of spawning new machines. This can be done on Kraken
-> Agents -> Groups page. When a particular group is selected, then
its details will be presented on a separate tab. On this tab, there is
a section Agents Deployment. So the deployment can be manual
(default) or automated to the particular cloud provider.
- AWS EC2
- AWS ECS
- Azure VM
- Kubernetes
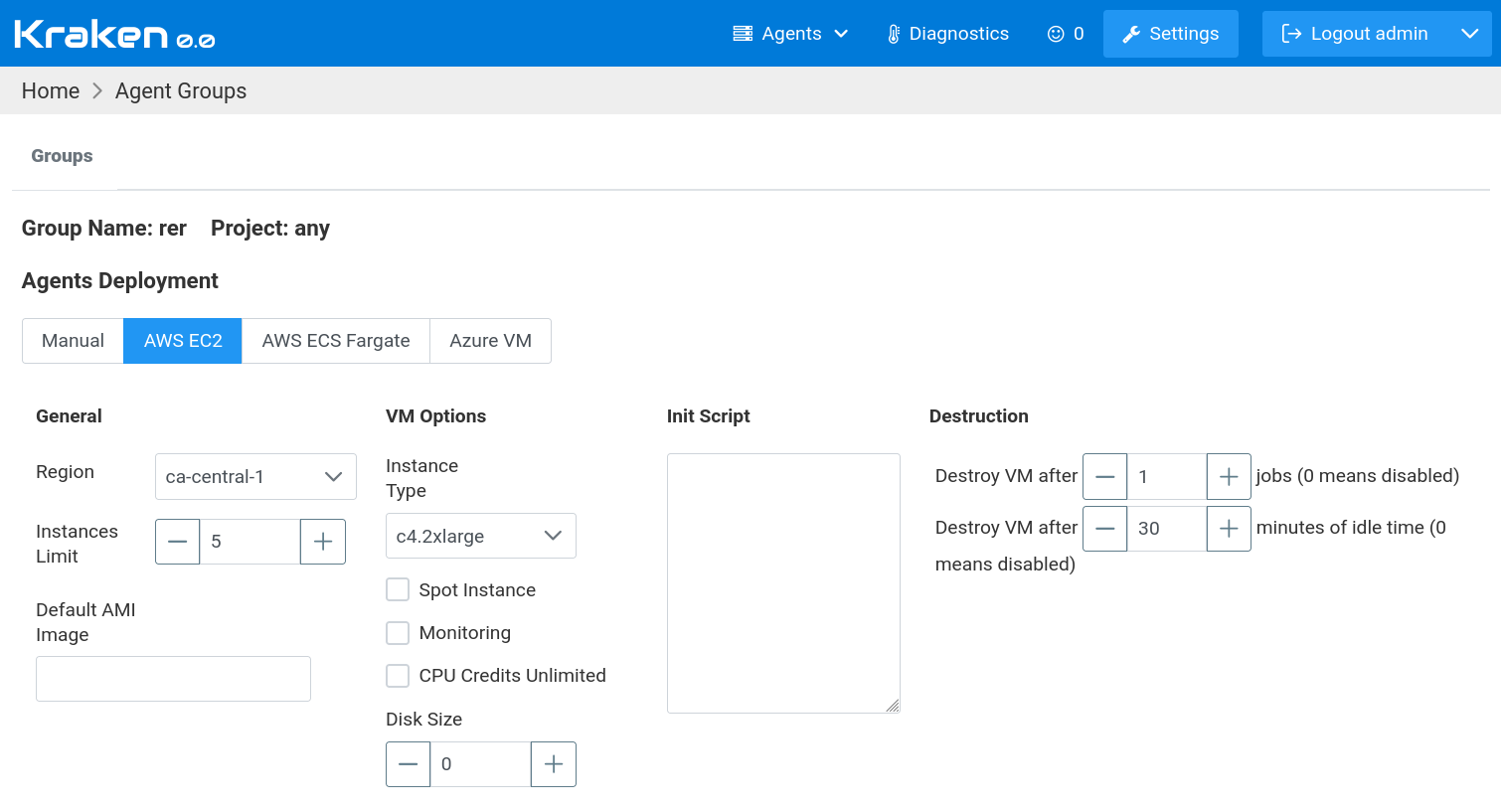
In the case of AWS EC2, jobs are executed in AWS EC2 VMs. There are
the following options that can be set:
The meaning of the settings is as follows.
In General section:
Region - AWS region where a machine will be spawned
Instances Limit - maximum number of spawned machines at a time
Default AMI Image - if AMI image is not provided in job definition then this one is used
In VM Options section:
Instance Type - EC2 instance type that should be used for spawned machines, the full list is available on AWS web page
Spot Instance - indicates where Spot instance should be used (AWS docs)
Monitoring - indicates if monitoring should be enabled (AWS docs)
CPU Credits Unlimited - this allows having more burst power, more in AWS docs
Disk Size - the size of root disk, if 0 then default size is used otherwise provided number is counted in GB
Init Script - a value of this text is passed as UserData to EC2 instance, generally, this is a script that is executing during the first boot of instance (AWS docs)
In Destruction section:
Destroy VM after N jobs - this indicates that the machine should be destroyed (terminated) after it is used in N Kraken jobs, default is 1, ie. machine is used once and then it is destroyed so each time a new fresh machine is used for each job; 0 means that this mechanism is disabled
Destroy VM after N minutes of idle time - this indicates that the machine should be destroyed (terminated) after it is not used in any Kraken jobs for a given number of minutes, default is 10 minutes, ie. a machine is destroyed if it sits idle for 10 minutes; 0 means that this mechanism is disabled
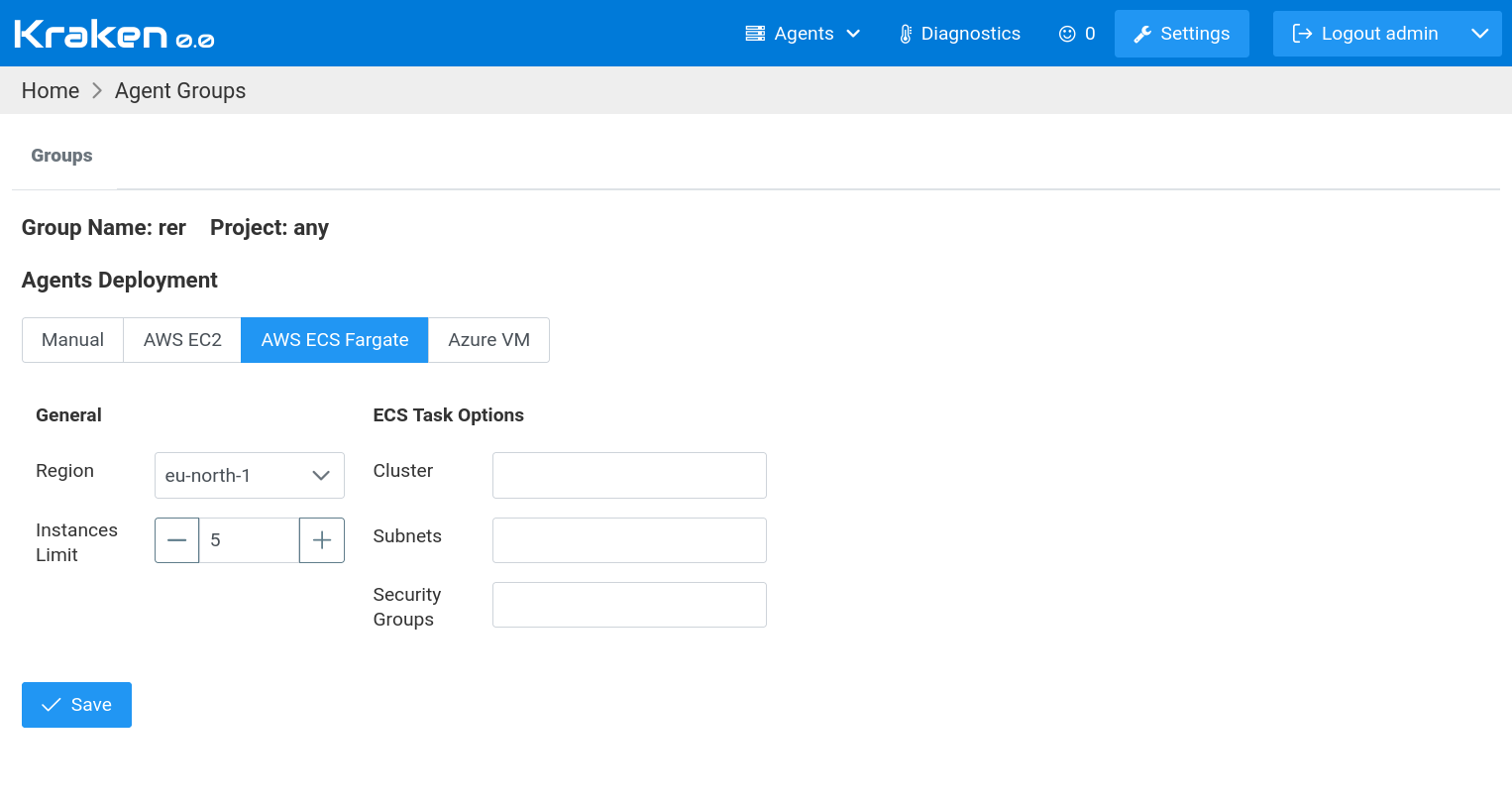
In the case of AWS ECS, jobs are executed in containers in AWS ECS
cluster. There are the following options that can be set:
The meaning of the settings is as follows.
In General section:
Region - AWS region where a machine will be spawned
Instances Limit - maximum number of spawned machines at a time
In ECS Task Options section:
Cluster - the name of ECS cluster
Subnets - a list of subnets IDs separated by comma
Security Group - ID of security group used for spawned tasks and their containers
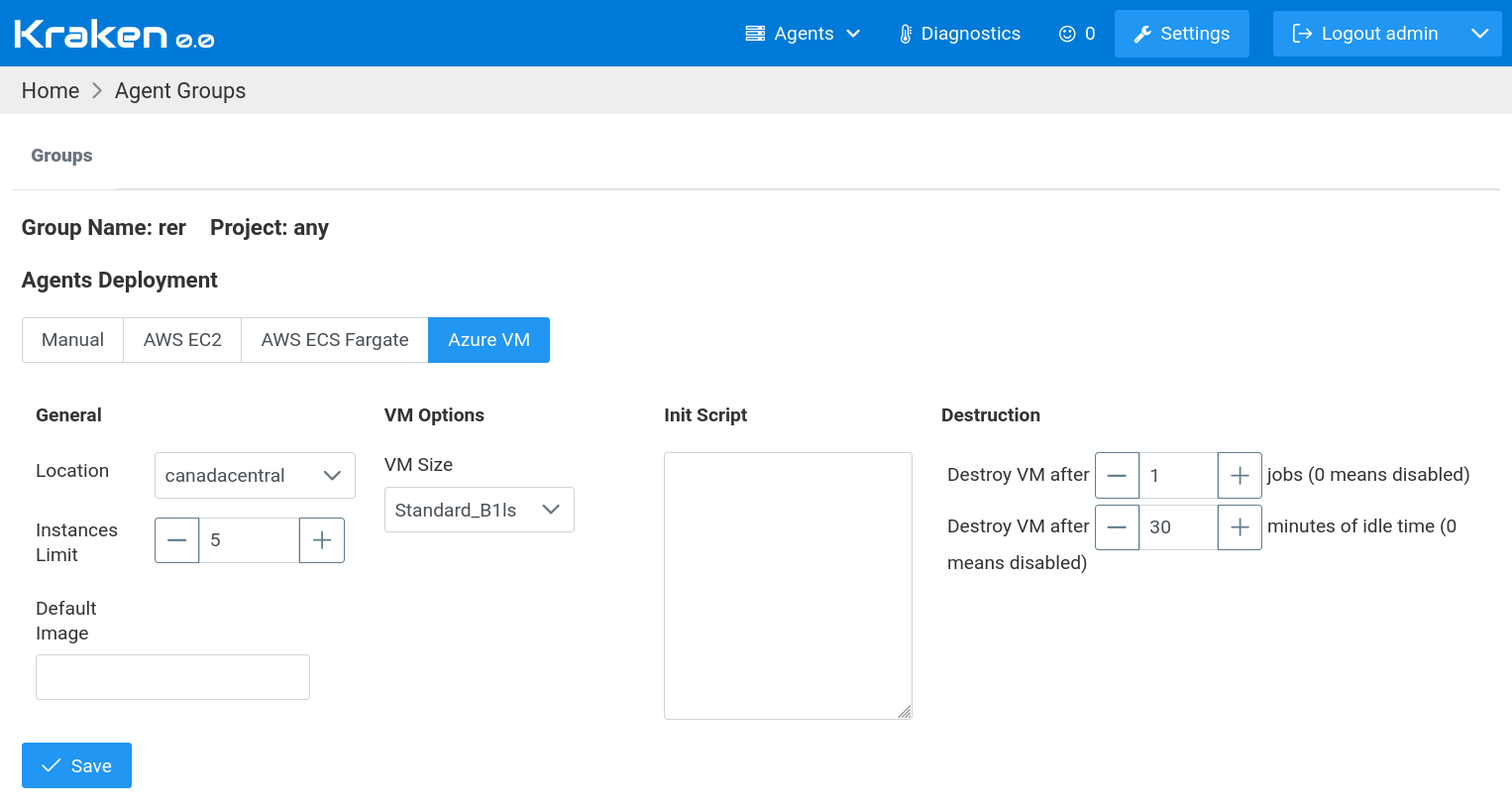
In the case of Azure VM, jobs are executed in virtual machines, in
Microsoft Azure VMs. There are the following options that can be set:
The meaning of the settings is as follows.
In General section:
Location - Azure location (region) where a machine will be spawned
Instances Limit - maximum number of spawned machines at a time
Default Image - if image is not provided in job definition then this one is used; the expected format is: publisher:offer:sku:version, e.g.: Canonical:0001-com-ubuntu-server-focal:20_04-lts:20.04.202109080
In VM Options section:
VM Size - Azure VM size that should be used for spawned machines; more about VM sizes can be found on Azure web page
Init Script - a value of this text is passed as user_data to VM instance, generally, this is a script that is executing during the first boot of instance
In Destruction section:
Destroy VM after N jobs - this indicates that the machine should be destroyed (terminated) after it is used in N Kraken jobs, default is 1, ie. machine is used once and then it is destroyed so each time a new fresh machine is used for each job; 0 means that this mechanism is disabled
Destroy VM after N minutes of idle time - this indicates that the machine should be destroyed (terminated) after it is not used in any Kraken jobs for a given number of minutes, default is 10 minutes, ie. a machine is destroyed if it sits idle for 10 minutes; 0 means that this mechanism is disabled
In the case of Kubernetes, jobs are executed in containers in a
Kubernetes cluster. Kubernetes cluster can be self-hosted or hosted in
a public cloud like AWS EKS. There are the following options that can
be set:
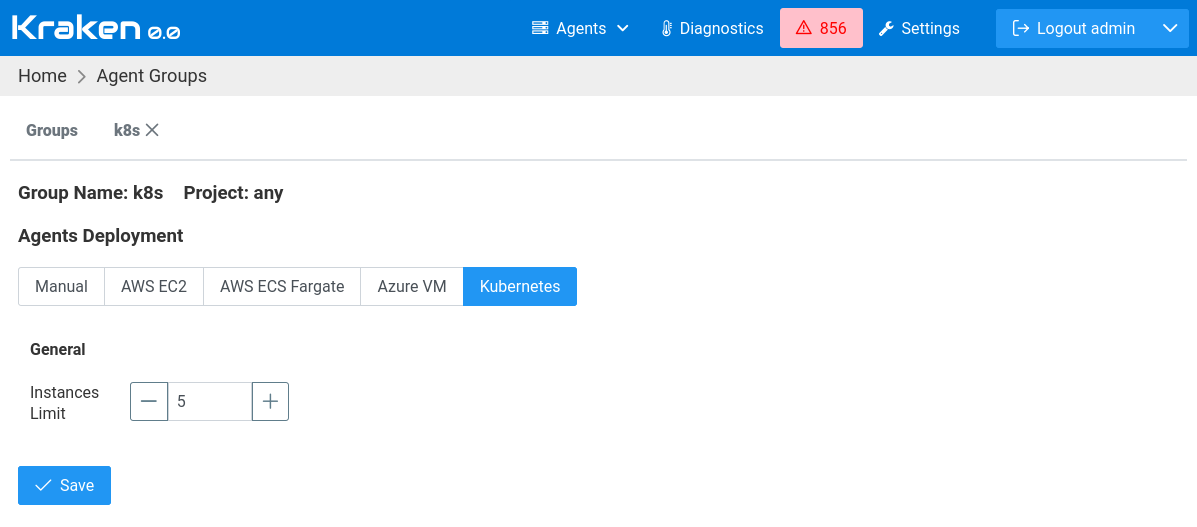
The meaning of the settings is as follows.
In General section:
Instances Limit - maximum number of spawned containers at a time
Usage
Now when a job is assigned to an agents group with configured Agents Deployment then a new machine will be spawned for that job if there are no available agents.