Entities & Terminology
Project
Project is the highest level entity, which separates things from other projects.

Branch
A project can contain multiple branches. Kraken Branch can represent a real source code
repository branch of a project, but it does not have to. Branches are usually used to model
multiple parallel, often independent, activity streams of a project. For example a customer-focused maintenance release
or a future-oriented development work. Branches may have different views of the source code repository,
use different sets of tools, have different scopes of tests, etc.

Stage
Each branch can contain multiple stages. A stage is used to define the detailed activities that will happen when a stage is executed.
Stages can be linked together to make one stage run after another stage is completed.
All stages that are not dependent (linked) and are ready to run, can be executed in parallel.
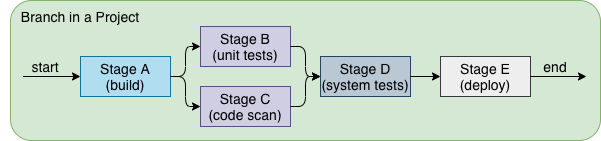
What is happening in a stage is defined by stage's workflow schema or just schema.
In schema there can be defines:
- one or more
stageparents triggersparametersconfigsjobsnotificationstimeout
Stage linking is defined by parents property in a stage. Parameters can be used to differentiate and parametrize jobs;
their values can be provided by user while starting a stage manually otherwise default values are used.
Configs allow for defining set of key-value pairs that statically define set of tests variants for execution.
Notifications can be used to inform users about stage result. There are several media available like email or Slack.
Timeout limits the time of whole stage executions. These assure us that the stage will be terminated if something really
bad is happening in jobs execution (e.g. they are hanging the machines).
More details about these schema properties are available in chapter Schema.
Jobs
Jobs describe what should be done in a stage. A stage can define multiple jobs and they all are run in parallel.
Job Steps
Each job contains one or more steps that describe operations to be run sequentially. A single step can be for example:
- execution of a shell command
- checking out sources from a repository
- running tests by a test tool
- running static checks by a linter
- and many more
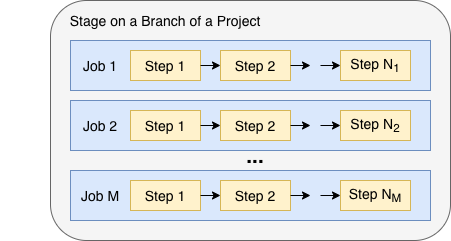
Job Environments
A Job contains definition of multiple environments. An environment specifies the following conditions for the execution of a job:
- agents group - pointing to machines with agents which will be used to run the steps
- operating system - OS that will be used on the machines
- configuration - one of
configurationsdefined in thestage
With the help of environments, the same job can be run on various combinations of target machines, operating systems and configuration parameters.
So environments allow for running the same job:
- on several different operating system;
- on several different hardware, e.g.: one with AMD CPU, another one with Intel CPU;
- with different tests configurations, e.g.: running the same benchmark but in several different resolutions.
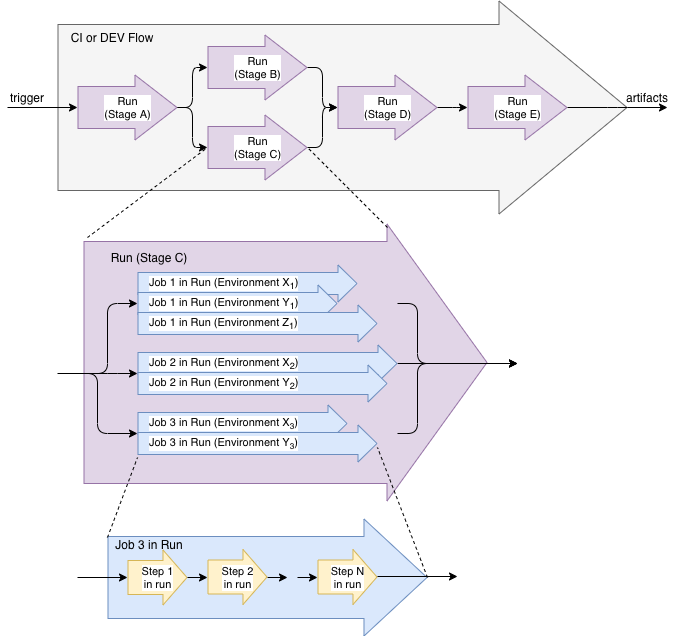
Flows & Runs
When Kraken triggers execution of stages, it starts a flow. A flow begins with the first stage (or group of stages) in the branch.
A stage that has been triggered and is executing, is called a run.
Subsequent runs are triggered by one of prior runs. Runs can also be triggered manually.
There can be two kinds of flows that are predefined by Kraken (see Kraken's Philosophy):
DEV flow- it represents pre-commit activities, for example it can be triggered by developer on demandCI flow- it represents post-commit activities, for example it can be triggered by commits to the production source code (master)
A run can dynamically determine in the context of which flow it is running - CI or DEV.
A job that is being executed as part of a run is called job in run. It has an individual execution status. Upon completion, it can
also have multiple test results or issues.
Similarily, a step that is being executed as part of a job in run is called step in run.
A job in run is executed (multiplied) for each of the environments defined in a stage.
Example of a Workflow Schema
Stage is defined using Python language.
def stage(ctx):
return {
"parent": "root",
"triggers": {
"parent": True,
"cron": "1 * * * *",
"interval": "10m",
"repository": True,
"webhook": True
},
"parameters": [],
"jobs": [{
"name": "make dist",
"steps": [{
"tool": "git",
"checkout": "https://github.com/frankhjung/python-helloworld.git",
"branch": "master"
}, {
"tool": "pytest",
"params": "tests/testhelloworld.py",
"cwd": "python-helloworld"
}],
"environments": [{
"system": "ubuntu-18.04",
"agents_group": "all",
"config": "default"
}]
}],
"notification": {
"slack": {"channel": "kk-results"},
"email": "[email protected]"
}
}